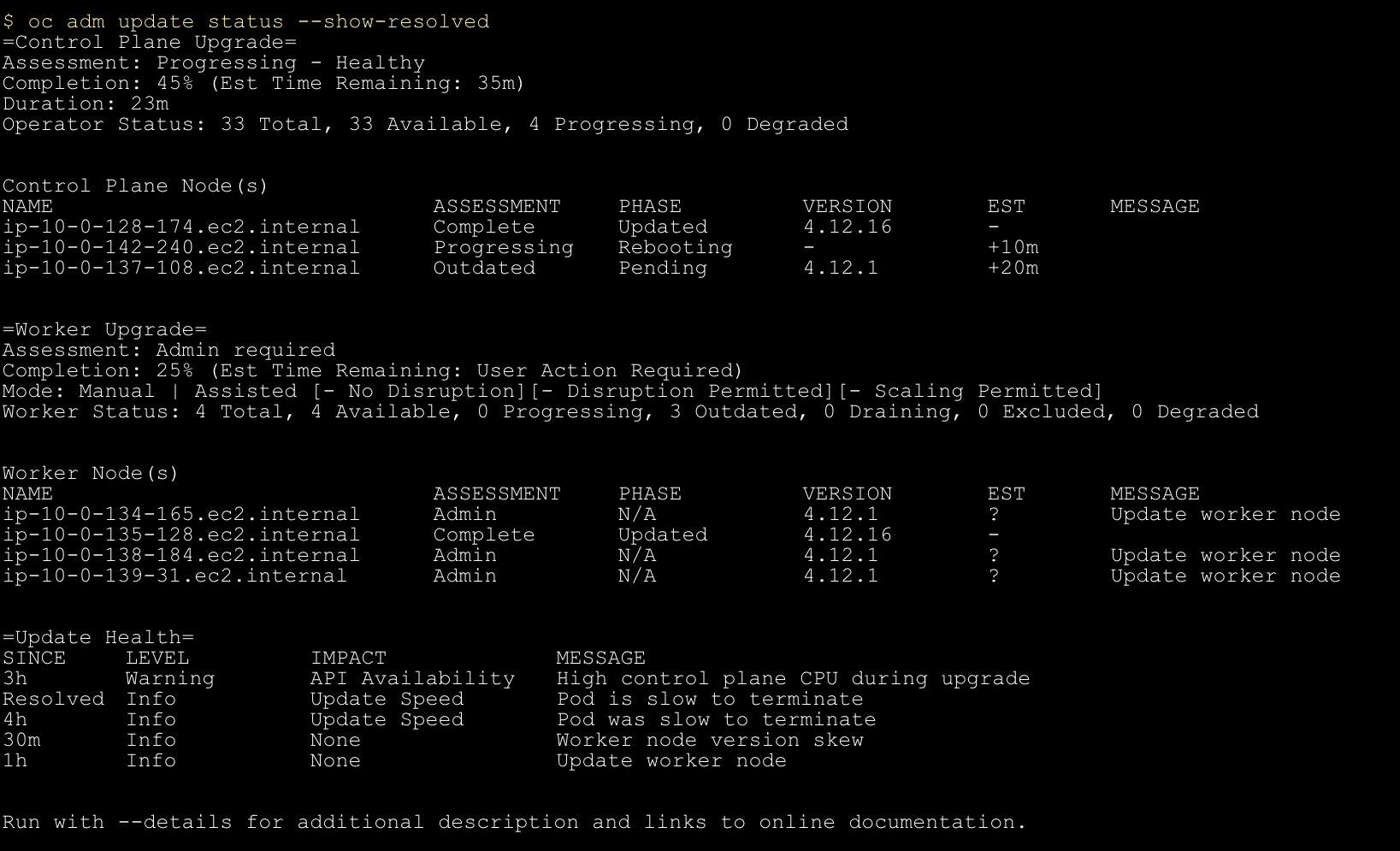
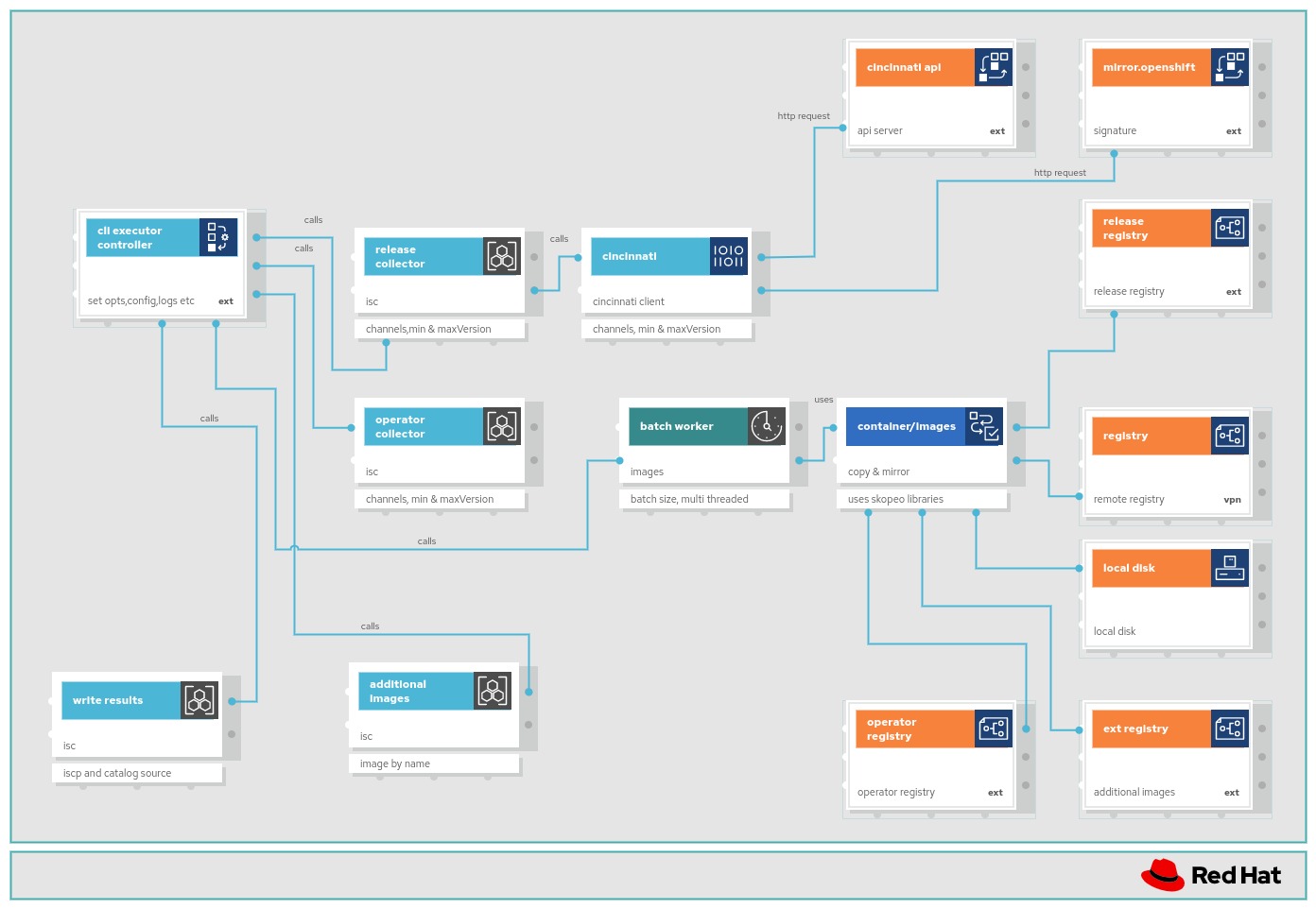
Complete Features
These features were completed when this image was assembled
Feature Overview (aka. Goal Summary)
Streamline and secure CLI interactions, improve backend validation processes, and refine user guidance and documentation for the hcp command and related functionalities.
Use Cases :
- Backend systems robustly handle validations especially to API-address featching and logic previously managed by CLI.
- Users can use the --render command independently of cluster connections, suitable for initial configurations.
- Clear guidance and documentation are available for configuring API server addresses and understanding platform-specific behaviors.
- Clarify which API server address is required for different platforms and configurations.
- Ensure the correct selection of nodes for API server address derivation.
- Improve the description of the --api-server-address flag, be concrete about which api server address is needed
- Add a note + the above to let folks to know they need to set it if they don’t want to be “connected” to a cluster.
Future:
- Improve APIServerAddress Selection?
- Add documentation about the restriction to have the management cluster being standalone
As a customer, I would like to deploy OpenShift On OpenStack, using the IPI workflow where my control plane would have 3 machines and each machine would have use a root volume (a Cinder volume attached to the Nova server) and also an attached ephemeral disk using local storage, that would only be used by etcd.
As this feature will be TechPreview in 4.15, this will only be implemented as a day 2 operation for now. This might or might not change in the future.
We know that etcd requires storage with strong performance capabilities and currently a root volume backed by Ceph has difficulties to provide these capabilities.
By also attaching local storage to the machine and mounting it for etcd would solve the performance issues that we saw when customers were using Ceph as the backend for the control plane disks.
Gophercloud already accepts to create a server with multiple ephemeral disks:
We need to figure out how we want to address that in CAPO, probably involving a new API; that later would be used in openshift (MAPO, and probably installer).
We'll also have to update the OpenStack Failure Domain in CPMS.
ARO (Azure) has conducted some benckmarks and is now recommending to put etcd on a separated data disk:
https://docs.google.com/document/d/1O_k6_CUyiGAB_30LuJFI6Hl93oEoKQ07q1Y7N2cBJHE/edit
Also interesting thread: https://groups.google.com/u/0/a/redhat.com/g/aos-devel/c/CztJzGWdsSM/m/jsPKZHSRAwAJ
- Day 2 install is documented here (this document was originally created for QE, as a FID).
- We need to document that when using rootVolumes for the Control Plane, etcd should be placed on a local ephemeral disk and we document how.
- We also need to update https://docs.openshift.com/container-platform/4.13/scalability_and_performance/recommended-performance-scale-practices/recommended-etcd-practices.html#move-etcd-different-disk_recommended-etcd-practices with 2 adjustments: the command that is used is mkfs.xfs -f and also we use /dev/vdb.
In this feature will follow up OCPBU-186 Image mirroring by tags.
OCPBU-186 implemented new API ImageDigestMirrorSet and ImageTagMirrorSet and rolling of them through MCO.
This feature will update the components using ImageContentSourcePolicy to use ImageDigestMirrorSet.
The list of the components: https://docs.google.com/document/d/11FJPpIYAQLj5EcYiJtbi_bNkAcJa2hCLV63WvoDsrcQ/edit?usp=sharing.
Migrate OpenShift Components to use the new Image Digest Mirror Set (IDMS)
This doc list openshift components currently use ICSP: https://docs.google.com/document/d/11FJPpIYAQLj5EcYiJtbi_bNkAcJa2hCLV63WvoDsrcQ/edit?usp=sharing
Plan for ImageDigestMirrorSet Rollout :
Epic: https://issues.redhat.com/browse/OCPNODE-521
4.13: Enable ImageDigestMirrorSet, both ICSP and ImageDigestMirrorSet objects are functional
- Document that ICSP is being deprecated and will be unsupported by 4.17 (to allow for EUS to EUS upgrades)
- Reject write to both ICSP and ImageDigestMirrorSet on the same cluster
4.14: Update OpenShift components to use IDMS
4.17: Remove support for ICSP within MCO
- Error out if an old ICSP object is used
As an openshift developer, I want --idms-file flag so that I can fetch image info from alternative mirror if --icsp-file gets deprecated.
BU Priority Overview
Create custom roles for GCP with minimal set of required permissions.
Goals
Enable customers to better scope credential permissions and create custom roles on GCP that only include the minimum subset of what is needed for OpenShift.
State of the Business
Some of the service accounts that CCO creates, e.g. service account with role roles/iam.serviceAccountUser provides elevated permissions that are not required/used by the requesting OpenShift components. This is because we use predefined roles for GCP that come with bunch of additional permissions. The goal is to create custom roles with only the required permissions.
Execution Plans
TBD
Epic Goal
- ...
Why is this important?
- …
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Evaluate if any of the GCP predefined roles in the credentials request manifest of Cluster Image Registry Operator give elevated permissions. Remove any such predefined role from spec.predefinedRoles field and replace it with required permissions in the new spec.permissions field.
The new GCP provider spec for credentials request CR is as follows:
type GCPProviderSpec struct {
metav1.TypeMeta `json:",inline"`
// PredefinedRoles is the list of GCP pre-defined roles
// that the CredentialsRequest requires.
PredefinedRoles []string `json:"predefinedRoles"`
// Permissions is the list of GCP permissions required to
// create a more fine-grained custom role to satisfy the
// CredentialsRequest.
// When both Permissions and PredefinedRoles are specified
// service account will have union of permissions from
// both the fields
Permissions []string `json:"permissions"`
// SkipServiceCheck can be set to true to skip the check whether the requested roles or permissions
// have the necessary services enabled
// +optional
SkipServiceCheck bool `json:"skipServiceCheck,omitempty"`
}
we can use the following command to check permissions associated with a GCP predefined role
gcloud iam roles describe <role_name>
The sample output for role roleViewer is as follows. The permission are listed in "includedPermissions" field.
[akhilrane@localhost cloud-credential-operator]$ gcloud iam roles describe roles/iam.roleViewer
description: Read access to all custom roles in the project.
etag: AA==
includedPermissions:
- iam.roles.get
- iam.roles.list
- resourcemanager.projects.get
- resourcemanager.projects.getIamPolicy
name: roles/iam.roleViewer
stage: GA
Evaluate if any of the GCP predefined roles in the credentials request manifests of OpenShift cluster operators give elevated permissions. Remove any such predefined role from spec.predefinedRoles field and replace it with required permissions in the new spec.permissions field.
The new GCP provider spec for credentials request CR is as follows:
type GCPProviderSpec struct {
metav1.TypeMeta `json:",inline"`
// PredefinedRoles is the list of GCP pre-defined roles
// that the CredentialsRequest requires.
PredefinedRoles []string `json:"predefinedRoles"`
// Permissions is the list of GCP permissions required to
// create a more fine-grained custom role to satisfy the
// CredentialsRequest.
// When both Permissions and PredefinedRoles are specified
// service account will have union of permissions from
// both the fields
Permissions []string `json:"permissions"`
// SkipServiceCheck can be set to true to skip the check whether the requested roles or permissions
// have the necessary services enabled
// +optional
SkipServiceCheck bool `json:"skipServiceCheck,omitempty"`
}
we can use the following command to check permissions associated with a GCP predefined role
gcloud iam roles describe <role_name>
The sample output for role roleViewer is as follows. The permission are listed in "includedPermissions" field.
[akhilrane@localhost cloud-credential-operator]$ gcloud iam roles describe roles/iam.roleViewer
description: Read access to all custom roles in the project.
etag: AA==
includedPermissions:
- iam.roles.get
- iam.roles.list
- resourcemanager.projects.get
- resourcemanager.projects.getIamPolicy
name: roles/iam.roleViewer
stage: GA
title: Role Viewer
Evaluate if any of the GCP predefined roles in the credentials request manifest of Cloud Controller Manager Operator give elevated permissions. Remove any such predefined role from spec.predefinedRoles field and replace it with required permissions in the new spec.permissions field.
The new GCP provider spec for credentials request CR is as follows:
type GCPProviderSpec struct {
metav1.TypeMeta `json:",inline"`
// PredefinedRoles is the list of GCP pre-defined roles
// that the CredentialsRequest requires.
PredefinedRoles []string `json:"predefinedRoles"`
// Permissions is the list of GCP permissions required to
// create a more fine-grained custom role to satisfy the
// CredentialsRequest.
// When both Permissions and PredefinedRoles are specified
// service account will have union of permissions from
// both the fields
Permissions []string `json:"permissions"`
// SkipServiceCheck can be set to true to skip the check whether the requested roles or permissions
// have the necessary services enabled
// +optional
SkipServiceCheck bool `json:"skipServiceCheck,omitempty"`
}
we can use the following command to check permissions associated with a GCP predefined role
gcloud iam roles describe <role_name>
The sample output for role roleViewer is as follows. The permission are listed in "includedPermissions" field.
[akhilrane@localhost cloud-credential-operator]$ gcloud iam roles describe roles/iam.roleViewer
description: Read access to all custom roles in the project.
etag: AA==
includedPermissions:
- iam.roles.get
- iam.roles.list
- resourcemanager.projects.get
- resourcemanager.projects.getIamPolicy
name: roles/iam.roleViewer
stage: GA
title: Role Viewer
Evaluate if any of the GCP predefined roles in the credentials request manifest of Cluster CAPI Operator give elevated permissions. Remove any such predefined role from spec.predefinedRoles field and replace it with required permissions in the new spec.permissions field.
The new GCP provider spec for credentials request CR is as follows:
type GCPProviderSpec struct {
metav1.TypeMeta `json:",inline"`
// PredefinedRoles is the list of GCP pre-defined roles
// that the CredentialsRequest requires.
PredefinedRoles []string `json:"predefinedRoles"`
// Permissions is the list of GCP permissions required to
// create a more fine-grained custom role to satisfy the
// CredentialsRequest.
// When both Permissions and PredefinedRoles are specified
// service account will have union of permissions from
// both the fields
Permissions []string `json:"permissions"`
// SkipServiceCheck can be set to true to skip the check whether the requested roles or permissions
// have the necessary services enabled
// +optional
SkipServiceCheck bool `json:"skipServiceCheck,omitempty"`
}
we can use the following command to check permissions associated with a GCP predefined role
gcloud iam roles describe <role_name>
The sample output for role roleViewer is as follows. The permission are listed in "includedPermissions" field.
[akhilrane@localhost cloud-credential-operator]$ gcloud iam roles describe roles/iam.roleViewer
description: Read access to all custom roles in the project.
etag: AA==
includedPermissions:
- iam.roles.get
- iam.roles.list
- resourcemanager.projects.get
- resourcemanager.projects.getIamPolicy
name: roles/iam.roleViewer
stage: GA
title: Role Viewer
These are phase 2 items from CCO-188
Moving items from other teams that need to be committed to for 4.13 this work to complete
Epic Goal
- Request to build list of specific permissions to run openshift on GCP - Components grant roles, but we need more granularity - Custom roles now allow ability to do this compared to when permissions capabilities were originally written for GCP
Why is this important?
- Some of the service accounts that CCO creates, e.g. service account with role roles/iam.serviceAccountUser provides elevated permissions that are not required/used by the requesting OpenShift components. This is because we use predefined roles for GCP that come with bunch of additional permissions. The goal is to create custom roles with only the required permissions.
Evaluate if any of the GCP predefined roles in the credentials request manifest of Cluster Storage Operator give elevated permissions. Remove any such predefined role from spec.predefinedRoles field and replace it with required permissions in the new spec.permissions field.
The new GCP provider spec for credentials request CR is as follows:
type GCPProviderSpec struct {
metav1.TypeMeta `json:",inline"`
// PredefinedRoles is the list of GCP pre-defined roles
// that the CredentialsRequest requires.
PredefinedRoles []string `json:"predefinedRoles"`
// Permissions is the list of GCP permissions required to
// create a more fine-grained custom role to satisfy the
// CredentialsRequest.
// When both Permissions and PredefinedRoles are specified
// service account will have union of permissions from
// both the fields
Permissions []string `json:"permissions"`
// SkipServiceCheck can be set to true to skip the check whether the requested roles or permissions
// have the necessary services enabled
// +optional
SkipServiceCheck bool `json:"skipServiceCheck,omitempty"`
}
we can use the following command to check permissions associated with a GCP predefined role
gcloud iam roles describe <role_name>
The sample output for role roleViewer is as follows. The permission are listed in "includedPermissions" field.
[akhilrane@localhost cloud-credential-operator]$ gcloud iam roles describe roles/iam.roleViewer
description: Read access to all custom roles in the project.
etag: AA==
includedPermissions:
- iam.roles.get
- iam.roles.list
- resourcemanager.projects.get
- resourcemanager.projects.getIamPolicy
name: roles/iam.roleViewer
stage: GA
title: Role Viewer
Evaluate if any of the GCP predefined roles in the credentials request manifest of Cluster Ingress Operator give elevated permissions. Remove any such predefined role from spec.predefinedRoles field and replace it with required permissions in the new spec.permissions field.
The new GCP provider spec for credentials request CR is as follows:
type GCPProviderSpec struct {
metav1.TypeMeta `json:",inline"`
// PredefinedRoles is the list of GCP pre-defined roles
// that the CredentialsRequest requires.
PredefinedRoles []string `json:"predefinedRoles"`
// Permissions is the list of GCP permissions required to
// create a more fine-grained custom role to satisfy the
// CredentialsRequest.
// When both Permissions and PredefinedRoles are specified
// service account will have union of permissions from
// both the fields
Permissions []string `json:"permissions"`
// SkipServiceCheck can be set to true to skip the check whether the requested roles or permissions
// have the necessary services enabled
// +optional
SkipServiceCheck bool `json:"skipServiceCheck,omitempty"`
}
we can use the following command to check permissions associated with a GCP predefined role
gcloud iam roles describe <role_name>
The sample output for role roleViewer is as follows. The permission are listed in "includedPermissions" field.
[akhilrane@localhost cloud-credential-operator]$ gcloud iam roles describe roles/iam.roleViewer
description: Read access to all custom roles in the project.
etag: AA==
includedPermissions:
- iam.roles.get
- iam.roles.list
- resourcemanager.projects.get
- resourcemanager.projects.getIamPolicy
name: roles/iam.roleViewer
stage: GA
title: Role Viewer
Evaluate if any of the GCP predefined roles in the credentials request manifest of Cluster Network Operator give elevated permissions. Remove any such predefined role from spec.predefinedRoles field and replace it with required permissions in the new spec.permissions field.
The new GCP provider spec for credentials request CR is as follows:
type GCPProviderSpec struct {
metav1.TypeMeta `json:",inline"`
// PredefinedRoles is the list of GCP pre-defined roles
// that the CredentialsRequest requires.
PredefinedRoles []string `json:"predefinedRoles"`
// Permissions is the list of GCP permissions required to
// create a more fine-grained custom role to satisfy the
// CredentialsRequest.
// When both Permissions and PredefinedRoles are specified
// service account will have union of permissions from
// both the fields
Permissions []string `json:"permissions"`
// SkipServiceCheck can be set to true to skip the check whether the requested roles or permissions
// have the necessary services enabled
// +optional
SkipServiceCheck bool `json:"skipServiceCheck,omitempty"`
}
we can use the following command to check permissions associated with a GCP predefined role
gcloud iam roles describe <role_name>
The sample output for role roleViewer is as follows. The permission are listed in "includedPermissions" field.
[akhilrane@localhost cloud-credential-operator]$ gcloud iam roles describe roles/iam.roleViewer
description: Read access to all custom roles in the project.
etag: AA==
includedPermissions:
- iam.roles.get
- iam.roles.list
- resourcemanager.projects.get
- resourcemanager.projects.getIamPolicy
name: roles/iam.roleViewer
stage: GA
title: Role Viewer
Update GCP Credentials Request manifest of the Cluster Network Operator to use new API field for requesting permissions.
Feature Overview
As an Infrastructure Administrator, I want to deploy OpenShift on Nutanix distributing the control plane and compute nodes across multiple regions and zones, forming different failure domains.
As an Infrastructure Administrator, I want to configure an existing OpenShift cluster to distribute the nodes across regions and zones, forming different failure domains.
Goals
Install OpenShift on Nutanix using IPI / UPI in multiple regions and zones.
Requirements (aka. Acceptance Criteria):
- Ensure Nutanix IPI can successfully be deployed with ODF across multiple zones (like we do with vSphere, AWS, GCP & Azure)
- Ensure zonal configuration in Nutanix using UPI is documented and tested
vSphere Implementation
This implementation would follow the same idea that has been done for vSphere. The following are the main PRs for vSphere:
https://github.com/openshift/enhancements/blob/master/enhancements/installer/vsphere-ipi-zonal.md
Existing vSphere documentation
Epic Goal
Nutanix Zonal: Multiple regions and zones support for Nutanix IPI and Assisted Installer
Note
- Nutanix Engineering team is driving this implementation based on the vSphere zonal implementation, led by Yanhua Li .
- The Installer team is expected to just review PRs.
- PRs are expected in these repos:
- https://github.com/openshift/api
- https://github.com/openshift/installer
- https://github.com/openshift/client-go
- https://github.com/openshift/cluster-control-plane-machine-set-operator
- https://github.com/openshift/machine-api-operator
- https://github.com/openshift/machine-api-provider-nutanix
- First PR https://github.com/openshift/api/pull/1578
As a user, I want to be able to spread control plane nodes for an OCP clusters across Prism Elements (zones).
Feature Overview (aka. Goal Summary)
Unify and update hosted control planes storage operators so that they have similar code patterns and can run properly in both standalone OCP and HyperShift's control plane.
Goals (aka. expected user outcomes)
- Simplify the operators with a unified code pattern
- Expose metrics from control-plane components
- Use proper RBACs in the guest cluster
- Scale the pods according to HostedControlPlane's AvailabilityPolicy
- Add proper node selector and pod affinity for mgmt cluster pods
Requirements (aka. Acceptance Criteria):
- OCP regression tests work in both standalone OCP and HyperShift
- Code in the operators looks the same
- Metrics from control-plane components are exposed
- Proper RBACs are used in the guest cluster
- Pods scale according to HostedControlPlane's AvailabilityPolicy
- Proper node selector and pod affinity is added for mgmt cluster pods
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. Initial completion during Refinement status.
Interoperability Considerations
Which other projects and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
Epic Goal*
Our current design of EBS driver operator to support Hypershift does not scale well to other drivers. Existing design will lead to more code duplication between driver operators and possibility of errors.
Why is this important? (mandatory)
An improved design will allow more storage drivers and their operators to be added to hypershift without requiring significant changes in the code internals.
Scenarios (mandatory)
Dependencies (internal and external) (mandatory)
What items must be delivered by other teams/groups to enable delivery of this epic.
Contributing Teams(and contacts) (mandatory)
Our expectation is that teams would modify the list below to fit the epic. Some epics may not need all the default groups but what is included here should accurately reflect who will be involved in delivering the epic.
- Development -
- Documentation -
- QE -
- PX -
- Others -
Acceptance Criteria (optional)
Provide some (testable) examples of how we will know if we have achieved the epic goal.
Drawbacks or Risk (optional)
Reasons we should consider NOT doing this such as: limited audience for the feature, feature will be superseded by other work that is planned, resulting feature will introduce substantial administrative complexity or user confusion, etc.
Done - Checklist (mandatory)
The following points apply to all epics and are what the OpenShift team believes are the minimum set of criteria that epics should meet for us to consider them potentially shippable. We request that epic owners modify this list to reflect the work to be completed in order to produce something that is potentially shippable.
- CI Testing - Basic e2e automationTests are merged and completing successfully
- Documentation - Content development is complete.
- QE - Test scenarios are written and executed successfully.
- Technical Enablement - Slides are complete (if requested by PLM)
- Engineering Stories Merged
- All associated work items with the Epic are closed
- Epic status should be “Release Pending”
Out CSI driver YAML files are mostly copy-paste from the initial CSI driver (AWS EBS?).
As OCP engineer, I want the YAML files to be generated, so we can keep consistency among the CSI drivers easily and make them less error-prone.
It should have no visible impact on the resulting operator behavior.
Finally switch both CI and ART to the refactored aws-ebs-csi-driver-operator.
The functionality and behavior should be the same as the existing operator, however, the code is completely new. There could be some rough edges. See https://github.com/openshift/enhancements/blob/master/enhancements/storage/csi-driver-operator-merge.md
Ci should catch the most obvious errors, however, we need to test features that we do not have in CI. Like:
- custom CA bundles
- cluster-wide proxy
- custom encryption keys used in install-config.yaml
- government cluster
- STS
- SNO
- and other
Feature Overview (aka. Goal Summary)
Enable support to bring your own encryption key (BYOK) for OpenShift on IBM Cloud VPC.
Goals (aka. expected user outcomes)
As a user I want to be able to provide my own encryption key when deploying OpenShift on IBM Cloud VPC so the cluster infrastructure objects, VM instances and storage objects, can use that user-managed key to encrypt the information.
Requirements (aka. Acceptance Criteria):
The Installer will provide a mechanism to specify a user-managed key that will be used to encrypt the data on the virtual machines that are part of the OpenShift cluster as well as any other persistent storage managed by the platform via Storage Classes.
Background
This feature is a required component for IBM's OpenShift replatforming effort.
Documentation Considerations
The feature will be documented as usual to guide the user while using their own key to encrypt the data on the OpenShift cluster running on IBM Cloud VPC
Epic Goal
- Review and support the IBM engineering team while enabling BYOK support for OpenShift on IBM Cloud VPC
Why is this important?
- As part of the replatform work IBM is doing for their OpenShift managed service this feature is Key for that work
Scenarios
- The installer will allow the user to provide their own key information to be used to encrypt the VMs storage and any storage object managed by OpenShift StorageClass objects
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
User Story:
As a (user persona), I want to be able to:
- Capability 1
- Capability 2
- Capability 3
so that I can achieve
- Outcome 1
- Outcome 2
- Outcome 3
Acceptance Criteria:
Description of criteria:
- Upstream documentation
- Point 1
- Point 2
- Point 3
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- (optional) https://github/com/link.to.enhancement/
- (optional) https://issues.redhat.com/link.to.spike
- Engineering detail 1
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
Epic Goal
- Update all images that we ship with OpenShift to the latest upstream releases and libraries.
- Exact content of what needs to be updated will be determined as new images are released upstream, which is not known at the beginning of OCP development work. We don't know what new features will be included and should be tested and documented. Especially new CSI drivers releases may bring new, currently unknown features. We expect that the amount of work will be roughly the same as in the previous releases. Of course, QE or docs can reject an update if it's too close to deadline and/or looks too big.
Traditionally we did these updates as bugfixes, because we did them after the feature freeze (FF).
Why is this important?
- We want to ship the latest software that contains new features and bugfixes.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
Update all OCP and kubernetes libraries in storage operators to the appropriate version for OCP release.
This includes (but is not limited to):
- Kubernetes:
- client-go
- controller-runtime
- OCP:
- library-go
- openshift/api
- openshift/client-go
- operator-sdk
Operators:
- aws-ebs-csi-driver-operator (in csi-operator)
- aws-efs-csi-driver-operator
- azure-disk-csi-driver-operator
- azure-file-csi-driver-operator
- openstack-cinder-csi-driver-operator
- gcp-pd-csi-driver-operator
- gcp-filestore-csi-driver-operator
- csi-driver-manila-operator
- vmware-vsphere-csi-driver-operator
- alibaba-disk-csi-driver-operator
- ibm-vpc-block-csi-driver-operator
- csi-driver-shared-resource-operator
- ibm-powervs-block-csi-driver-operator
- secrets-store-csi-driver-operator
- cluster-storage-operator
- cluster-csi-snapshot-controller-operator
- local-storage-operator
- vsphere-problem-detector
EOL, do not upgrade:
- github.com/oVirt/csi-driver-operator
Update the driver to the latest upstream release. Notify QE and docs with any new features and important bugfixes that need testing or documentation.
(Using separate cards for each driver because these updates can be more complicated)
Goal
Hardware RAID support on Dell, Supermicro and HPE with Metal3.
Why is this important
Setting up RAID devices is a common operation in the hardware for OpenShift nodes. While there's been work at Fujitsu for configuring RAID in Fujitsu servers with Metal3, we don't support any generic interface with Redfish to extend this support and set it up it in Metal3.
Dell, Supermicro and HPE, which are the most common hardware platforms we find in our customers environments are the main target.
Goal
Hardware RAID support on Dell with Metal3.
Why is this important
Setting up RAID devices is a common operation in the hardware for OpenShift nodes. While there's been work at Fujitsu for configuring RAID in Fujitsu servers with Metal3, we don't support any generic interface with Redfish to extend this support and set it up it in Metal3 for Dell, which are the most common hardware platforms we find in our customers environments.
Before implementing generic support, we need to understand the implications of enabling an interface in Metal3 to allow it on multiple hardware types.
Scope questions
- Changes in Ironic?
- Maybe, but it should be there?
- Changes in Metal3?
- Hopefully small, it should be there for Fujitsu
- Changes in OpenShift?
- Hopefully small, it should be there for Fujitsu
- Spec/Design/Enhancements?
- Ironic: no (supports this already)
- Metal3: no (ditto)
- OpenShift:
https://github.com/openshift/enhancements/blob/master/enhancements/baremetal/baremetal-config-raid-and-bios.md
- Dependencies on other teams?
- No
While rendering BMO in https://issues.redhat.com/browse/METAL-829 the node cpu_arch was hardcoded to x86_64
We should use bmh.Spec.Architecture instead to be more future proof
Feature Overview
Extend OpenShift on IBM Cloud integration with additional features to pair the capabilities offered for this provider integration to the ones available in other cloud platforms.
Goals
Extend the existing features while deploying OpenShift on IBM Cloud.
Background, and strategic fit
This top level feature is going to be used as a placeholder for the IBM team who is working on new features for this integration in an effort to keep in sync their existing internal backlog with the corresponding Features/Epics in Red Hat's Jira.
Epic Goal
- Enable installation of disconnected clusters on IBM Cloud. This epic will track associated work.
Why is this important?
- Would like to support this at GA. It is an 'optional' feature that will be pursued after completing private cluster installation support ( https://issues.redhat.com/browse/SPLAT-731 ).
Scenarios
- Install a disconnected cluster on IBM Cloud.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
User Story:
A user currently is not able to create a Disconnected cluster, using IPI, on IBM Cloud.
Currently, support for BYON and Private clusters does exist on IBM Cloud, but support to override IBM Cloud Service endpoints does not exist, which is required to allow for Disconnected support to function (reach IBM Cloud private endpoints).
Description:
IBM dependent components of OCP will need to add support to use a set of endpoint override values in order to reach IBM Cloud Services in Disconnected environments.
The Image Registry components will need to be able to allow all API calls to IBM Cloud Services, be directed to these endpoint values, in order to communicate in environments where the Public or default IBM Cloud Service endpoint is not available.
The endpoint overrides are available via the infrastructure/cluster (.status.platformStatus.ibmcloud.serviceEndpoints) resource, which is how a majority of components are consuming cluster specific configurations (Ingress, MAPI, etc.). It will be structured as such
apiVersion: config.openshift.io/v1 kind: Infrastructure metadata: creationTimestamp: "2023-10-04T22:02:15Z" generation: 1 name: cluster resourceVersion: "430" uid: b923c3de-81fc-4a0e-9fdb-8c4c337fba08 spec: cloudConfig: key: config name: cloud-provider-config platformSpec: type: IBMCloud status: apiServerInternalURI: https://api-int.us-east-disconnect-21.ipi-cjschaef-dns.com:6443 apiServerURL: https://api.us-east-disconnect-21.ipi-cjschaef-dns.com:6443 controlPlaneTopology: HighlyAvailable cpuPartitioning: None etcdDiscoveryDomain: "" infrastructureName: us-east-disconnect-21-gtbwd infrastructureTopology: HighlyAvailable platform: IBMCloud platformStatus: ibmcloud: dnsInstanceCRN: 'crn:v1:bluemix:public:dns-svcs:global:a/fa4fd9fa0695c007d1fdcb69a982868c:f00ac00e-75c2-4774-a5da-44b2183e31f7::' location: us-east providerType: VPC resourceGroupName: us-east-disconnect-21-gtbwd serviceEndpoints: - name: iam url: https://private.us-east.iam.cloud.ibm.com - name: vpc url: https://us-east.private.iaas.cloud.ibm.com/v1 - name: resourcecontroller url: https://private.us-east.resource-controller.cloud.ibm.com - name: resourcemanager url: https://private.us-east.resource-controller.cloud.ibm.com - name: cis url: https://api.private.cis.cloud.ibm.com - name: dnsservices url: https://api.private.dns-svcs.cloud.ibm.com/v1 - name: cis url: https://s3.direct.us-east.cloud-object-storage.appdomain.cloud type: IBMCloud
The CCM is currently relying on updates to the openshift-cloud-controller-manager/cloud-conf configmap, in order to override its required IBM Cloud Service endpoints, such as:
data: config: |+ [global] version = 1.1.0 [kubernetes] config-file = "" [provider] accountID = ... clusterID = temp-disconnect-7m6rw cluster-default-provider = g2 region = eu-de g2Credentials = /etc/vpc/ibmcloud_api_key g2ResourceGroupName = temp-disconnect-7m6rw g2VpcName = temp-disconnect-7m6rw-vpc g2workerServiceAccountID = ... g2VpcSubnetNames = temp-disconnect-7m6rw-subnet-compute-eu-de-1,temp-disconnect-7m6rw-subnet-compute-eu-de-2,temp-disconnect-7m6rw-subnet-compute-eu-de-3,temp-disconnect-7m6rw-subnet-control-plane-eu-de-1,temp-disconnect-7m6rw-subnet-control-plane-eu-de-2,temp-disconnect-7m6rw-subnet-control-plane-eu-de-3 iamEndpointOverride = https://private.iam.cloud.ibm.com g2EndpointOverride = https://eu-de.private.iaas.cloud.ibm.com rmEndpointOverride = https://private.resource-controller.cloud.ibm.com
Acceptance Criteria:
Installer validates and injects user provided endpoint overrides into cluster deployment process and the Image Registry components use specified endpoints and start up properly.
Template:
Networking Definition of Planned
Epic Template descriptions and documentation
Epic Goal
With ovn-ic we have multiple actors (zones) setting status on some CRs. We need to make sure individual zone statuses are reported and then optionally merged to a single status
Why is this important?
Without that change zones will overwrite each others statuses.
Planning Done Checklist
The following items must be completed on the Epic prior to moving the Epic from Planning to the ToDo status
 Priority+ is set by engineering
Priority+ is set by engineering- Epic must be Linked to a +Parent Feature
 Target version+ must be set
Target version+ must be set- Assignee+ must be set
- (Enhancement Proposal is Implementable
- (No outstanding questions about major work breakdown
- (Are all Stakeholders known? Have they all been notified about this item?
- Does this epic affect SD? {}Have they been notified{+}? (View plan definition for current suggested assignee)
- Please use the “Discussion Needed: Service Delivery Architecture Overview” checkbox to facilitate the conversation with SD Architects. The SD architecture team monitors this checkbox which should then spur the conversation between SD and epic stakeholders. Once the conversation has occurred, uncheck the “Discussion Needed: Service Delivery Architecture Overview” checkbox and record the outcome of the discussion in the epic description here.
- The guidance here is that unless it is very clear that your epic doesn’t have any managed services impact, default to use the Discussion Needed checkbox to facilitate that conversation.
Additional information on each of the above items can be found here: Networking Definition of Planned
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement
details and documents.
...
Dependencies (internal and external)
1.
...
Previous Work (Optional):
1. …
Open questions::
1. …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
< High-Level description of the feature ie: Executive Summary >
Goals
Cluster administrators need an in-product experience to discover and install new Red Hat offerings that can add high value to developer workflows.
Requirements
| Requirements | Notes | IS MVP |
| Discover new offerings in Home Dashboard | Y | |
| Access details outlining value of offerings | Y | |
| Access step-by-step guide to install offering | N | |
| Allow developers to easily find and use newly installed offerings | Y | |
| Support air-gapped clusters | Y |
< What are we making, for who, and why/what problem are we solving?>
Out of scope
Discovering solutions that are not available for installation on cluster
Dependencies
No known dependencies
Background, and strategic fit
Assumptions
None
Customer Considerations
Documentation Considerations
Quick Starts
What does success look like?
QE Contact
Impact
Related Architecture/Technical Documents
Done Checklist
- Acceptance criteria are met
- Non-functional properties of the Feature have been validated (such as performance, resource, UX, security or privacy aspects)
- User Journey automation is delivered
- Support and SRE teams are provided with enough skills to support the feature in production environment
Problem:
Cluster admins need to be guided to install RHDH on the cluster.
Goal:
Enable admins to discover RHDH, be guided to installing it on the cluster, and verifying its configuration.
Why is it important?
RHDH is a key multi-cluster offering for developers. This will enable customers to self-discover and install RHDH.
Acceptance criteria:
- Show RHDH card in Admin->Dashboard view
- Enable link to RHDH documentation from the card
- Quick start to install RHDH operator
- Guided flow to installation and configuration of operator from Quick Start
- RHDH UI link in top menu
- Successful log in to RHDH
Dependencies (External/Internal):
RHDH operator
Design Artifacts:
Exploration:
Note:
Description of problem:
The OpenShift Console QuickStarts promotes RHDH but also includes Janus IDP information.
The Janus IDP quick starts should be removed and all information about Janus IDP should be removed.
Version-Release number of selected component (if applicable):
4.15
How reproducible:
Always
Steps to Reproduce:
Just navigate to Quick starts and select the "Install Red Hat Developer Hub (RHDH) with an Operator" quick starts
Actual results:
- The RHDH Operator Quick start contains some information and links to Janus IDP.
- The Janus IDP Quick start exists and is similar to the RHDH one.
Expected results:
- The RHDH Operator Quick start must not contain information about Janus IDP.
- The Janus IDP Quick start should be removed
Additional info:
Initial PR: https://github.com/openshift/console-operator/pull/806
Feature Overview (aka. Goal Summary)
Consolidated Enhancement of HyperShift/KubeVirt Provider Post GA
This feature aims to provide a comprehensive enhancement to the HyperShift/KubeVirt provider integration post its GA release.
By consolidating CSI plugin improvements, core improvements, and networking enhancements, we aim to offer a more robust, efficient, and user-friendly experience.
Goals (aka. expected user outcomes)
- User Persona: Cluster service providers / SRE
- Functionality:
- Expanded CSI capabilities.
- Improved core functionalities of the KubeVirt Provider
- Enhanced networking capabilities.
Goal
Post GA quality of life improvements for the HyperShift/KubeVirt core
User Stories
Non-Requirements
Notes
- Any additional details or decisions made/needed
Done Checklist
| Who | What | Reference |
|---|---|---|
| DEV | Upstream roadmap issue (or individual upstream PRs) | <link to GitHub Issue> |
| DEV | Upstream documentation merged | <link to meaningful PR> |
| DEV | gap doc updated | <name sheet and cell> |
| DEV | Upgrade consideration | <link to upgrade-related test or design doc> |
| DEV | CEE/PX summary presentation | label epic with cee-training and add a <link to your support-facing preso> |
| QE | Test plans in Polarion | <link or reference to Polarion> |
| QE | Automated tests merged | <link or reference to automated tests> |
| DOC | Downstream documentation merged | <link to meaningful PR> |
the rbac required for external infra needs to be documented on this page.
https://hypershift-docs.netlify.app/how-to/kubevirt/external-infrastructure/
Currently there is no option to influence on the placement of the VMs of an hosted cluster with kubevirt provider. the existing NodeSelector in HostedCluster are influencing only the pods in the hosted control plane namespace.
The goal is to introduce an new field in .spec.platform.kubevirt stanza in NodePool for node selector, propagate it to the VirtualMachineSpecTemplate, and expose this in the hypershift and hcp CLIs.
Epic Goal
- Add an API extension for North-South IPsec.
- close gaps from
SDN-3604- mainly around upgrade - add telemetry
Why is this important?
- without API, customers are forced to use MCO. this brings with it a set of limitations (mainly reboot per change and the fact that config is shared among each pool, can't do per node configuration)
- better upgrade solution will give us the ability to support a single host based implementation
- telemetry will give us more info on how widely is ipsec used.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- Must allow for the possibility of offloading the IPsec encryption to a SmartNIC.
- nmstate
- k8s-nmstate
- easier mechanism for cert injection (??)
- telemetry
Dependencies (internal and external)
Related:
- ITUP-44 - OpenShift support for North-South OVN IPSec
- HATSTRAT-33 - Encrypt All Traffic to/from Cluster (aka IPSec as a Service)
Previous Work (Optional):
SDN-717- Support IPSEC on ovn-kubernetesSDN-3604- Fully supported non-GA N-S IPSec implementation using machine config.
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Feature Overview (aka. Goal Summary)
oc, the openshift CLI, needs as close to feature parity as we can get without the built-in oauth server and its associated user and group management. This will enable scripts, documentation, blog posts, and knowledge base articles to function across all form factors and the same form factor with different configurations.
Goals (aka. expected user outcomes)
CLI users and scripts should be usable in a consistent way regardless of the token issuer configuration.
Requirements (aka. Acceptance Criteria):
A list of specific needs or objectives that a feature must deliver in order to be considered complete. Be sure to include nonfunctional requirements such as security, reliability, performance, maintainability, scalability, usability, etc. Initial completion during Refinement status.
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. If the feature extends existing functionality, provide a link to its current documentation. Initial completion during Refinement status.
Interoperability Considerations
Which other projects, including ROSA/OSD/ARO, and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
Epic Goal*
What is our purpose in implementing this? What new capability will be available to customers?
oc login needs to work without the embedded oauth server
Why is this important? (mandatory)
We are removing the embedded oauth-server and we utilize a special oauthclient in order to make our login flows functional
This allows documentation, scripts, etc to be functional and consistent with the last 10 years of our product.
This may require vendoring entire CLI plugins. It may require new kubeconfig shapes.
Scenarios (mandatory)
Provide details for user scenarios including actions to be performed, platform specifications, and user personas.
Dependencies (internal and external) (mandatory)
What items must be delivered by other teams/groups to enable delivery of this epic.
Contributing Teams(and contacts) (mandatory)
Our expectation is that teams would modify the list below to fit the epic. Some epics may not need all the default groups but what is included here should accurately reflect who will be involved in delivering the epic.
- Development -
- Documentation -
- QE -
- PX -
- Others -
Acceptance Criteria (optional)
Provide some (testable) examples of how we will know if we have achieved the epic goal.
Drawbacks or Risk (optional)
Reasons we should consider NOT doing this such as: limited audience for the feature, feature will be superseded by other work that is planned, resulting feature will introduce substantial administrative complexity or user confusion, etc.
Done - Checklist (mandatory)
The following points apply to all epics and are what the OpenShift team believes are the minimum set of criteria that epics should meet for us to consider them potentially shippable. We request that epic owners modify this list to reflect the work to be completed in order to produce something that is potentially shippable.
- CI Testing - Basic e2e automationTests are merged and completing successfully
- Documentation - Content development is complete.
- QE - Test scenarios are written and executed successfully.
- Technical Enablement - Slides are complete (if requested by PLM)
- Engineering Stories Merged
- All associated work items with the Epic are closed
- Epic status should be “Release Pending”
Description of problem:
Introduce --issuer-url flag in oc login .
Version-Release number of selected component (if applicable):
[xxia@2024-03-01 21:03:30 CST my]$ oc version --client Client Version: 4.16.0-0.ci-2024-03-01-033249 Kustomize Version: v5.0.4-0.20230601165947-6ce0bf390ce3 [xxia@2024-03-01 21:03:50 CST my]$ oc get clusterversion NAME VERSION AVAILABLE PROGRESSING SINCE STATUS version 4.16.0-0.ci-2024-02-29-213249 True False 8h Cluster version is 4.16.0-0.ci-2024-02-29-213249
How reproducible:
Always
Steps to Reproduce:
1. Launch fresh HCP cluster.
2. Login to https://entra.microsoft.com. Register application and set properly.
3. Prepare variables.
HC_NAME=hypershift-ci-267920
MGMT_KUBECONFIG=/home/xxia/my/env/xxia-hs416-2-267920-4.16/kubeconfig
HOSTED_KUBECONFIG=/home/xxia/my/env/xxia-hs416-2-267920-4.16/hypershift-ci-267920.kubeconfig
AUDIENCE=7686xxxxxx
ISSUER_URL=https://login.microsoftonline.com/64dcxxxxxxxx/v2.0
CLIENT_ID=7686xxxxxx
CLIENT_SECRET_VALUE="xxxxxxxx"
CLIENT_SECRET_NAME=console-secret
4. Configure HC without oauthMetadata.
[xxia@2024-03-01 20:29:21 CST my]$ oc create secret generic console-secret -n clusters --from-literal=clientSecret=$CLIENT_SECRET_VALUE --kubeconfig $MGMT_KUBECONFIG
[xxia@2024-03-01 20:34:05 CST my]$ oc patch hc $HC_NAME -n clusters --kubeconfig $MGMT_KUBECONFIG --type=merge -p="
spec:
configuration:
authentication:
oauthMetadata:
name: ''
oidcProviders:
- claimMappings:
groups:
claim: groups
prefix: 'oidc-groups-test:'
username:
claim: email
prefixPolicy: Prefix
prefix:
prefixString: 'oidc-user-test:'
issuer:
audiences:
- $AUDIENCE
issuerURL: $ISSUER_URL
name: microsoft-entra-id
oidcClients:
- clientID: $CLIENT_ID
clientSecret:
name: $CLIENT_SECRET_NAME
componentName: console
componentNamespace: openshift-console
type: OIDC
"
Wait pods to renew:
[xxia@2024-03-01 20:52:41 CST my]$ oc get po -n clusters-$HC_NAME --kubeconfig $MGMT_KUBECONFIG --sort-by metadata.creationTimestamp
...
certified-operators-catalog-7ff9cffc8f-z5dlg 1/1 Running 0 5h44m
kube-apiserver-6bd9f7ccbd-kqzm7 5/5 Running 0 17m
kube-apiserver-6bd9f7ccbd-p2fw7 5/5 Running 0 15m
kube-apiserver-6bd9f7ccbd-fmsgl 5/5 Running 0 13m
openshift-apiserver-7ffc9fd764-qgd4z 3/3 Running 0 11m
openshift-apiserver-7ffc9fd764-vh6x9 3/3 Running 0 10m
openshift-apiserver-7ffc9fd764-b7znk 3/3 Running 0 10m
konnectivity-agent-577944765c-qxq75 1/1 Running 0 9m42s
hosted-cluster-config-operator-695c5854c-dlzwh 1/1 Running 0 9m42s
cluster-version-operator-7c99cf68cd-22k84 1/1 Running 0 9m42s
konnectivity-agent-577944765c-kqfpq 1/1 Running 0 9m40s
konnectivity-agent-577944765c-7t5ds 1/1 Running 0 9m37s
5. Check console login and oc login.
$ export KUBECONFIG=$HOSTED_KUBECONFIG
$ curl -ksS $(oc whoami --show-server)/.well-known/oauth-authorization-server
{
"issuer": "https://:0",
"authorization_endpoint": "https://:0/oauth/authorize",
"token_endpoint": "https://:0/oauth/token",
...
}
Check console login, it succeeds, console upper right shows correctly user name oidc-user-test:xxia@redhat.com.
Check oc login:
$ rm -rf ~/.kube/cache/oc/
$ oc login --exec-plugin=oc-oidc --client-id=$CLIENT_ID --client-secret=$CLIENT_SECRET_VALUE --extra-scopes=email --callback-port=8080
error: oidc authenticator error: oidc discovery error: Get "https://:0/.well-known/openid-configuration": dial tcp :0: connect: connection refused
error: oidc authenticator error: oidc discovery error: Get "https://:0/.well-known/openid-configuration": dial tcp :0: connect: connection refused
Unable to connect to the server: getting credentials: exec: executable oc failed with exit code 1
Actual results:
Console login succeeds. oc login fails.
Expected results:
oc login should also succeed.
Additional info:{}
Feature Overview (aka. Goal Summary)
As part of the deprecation progression of the openshift-sdn CNI plug-in, remove it as an install-time option for new 4.15+ release clusters.
Goals (aka. expected user outcomes)
The openshift-sdn CNI plug-in is sunsetting according to the following progression:
- deprecation notice delivered at 4.14 (Release Notes, What's Next presentation)
- removal as an install-time option at 4.15+
- removal as an option and EOL support at 4.17 GA
Requirements (aka. Acceptance Criteria):
- The openshift-sdn CNI plug-in will no longer be an install-time option for newly installed 4.15+ clusters across installation options.
- Customer clusters currently using openshift-sdn that upgrade to 4.15 or 4.16 with openshift-sdn will remain fully supported.
- EUS customers using openshift-sdn on an earlier release (e.g. 4.12 or 4.14) will still be able to upgrade to 4.16 and receive full support of the openshift-sdn plug-in.
Questions to Answer (Optional):
- Will clusters using openshift-sdn and upgrading from earlier versions to 4.15 and 4.16 still be supported?
- YES
- My customer has a hard requirement for the ability to install openshift-sdn 4.15 clusters. Is there any exceptions to support that?
- Customers can file a Support Exception for consideration, and the reason for the requirement (expectation: rare) must be clarified.
Out of Scope
Background
All development effort is directed to the default primary CNI plug-in, ovn-kubernetes, which has feature parity with the older openshift-sdn CNI plug-in that has been feature frozen for the entire 4.x timeframe. In order to best serve our customers now and in the future, we are reducing our support footprint to the dominant plug-in, only.
Documentation Considerations
- Product Documentation updates to reflect the install-time option change.
Epic Goal
The openshift-sdn CNI plug-in is sunsetting according to the following progression:
- deprecation notice delivered at 4.14 (Release Notes, What's Next presentation)
- removal as an install-time option at 4.15+
- removal as an option and EOL support at 4.17 GA
Why is this important?
All development effort is directed to the default primary CNI plug-in, ovn-kubernetes, which has feature parity with the older openshift-sdn CNI plug-in that has been feature frozen for the entire 4.x timeframe. In order to best serve our customers now and in the future, we are reducing our support footprint to the dominant plug-in, only.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- The openshift-sdn CNI plug-in will no longer be an install-time option for newly installed 4.15+ clusters across installation options.
- Customer clusters currently using openshift-sdn that upgrade to 4.15 or 4.16 with openshift-sdn will remain fully supported.
- EUS customers using openshift-sdn on an earlier release (e.g. 4.12 or 4.14) will still be able to upgrade to 4.16 and receive full support of the openshift-sdn plug-in.
Open questions::
- Will clusters using openshift-sdn and upgrading from earlier versions to 4.15 and 4.16 still be supported?
- YES
- My customer has a hard requirement for the ability to install openshift-sdn 4.15 clusters. Is there any exceptions to support that?
- Customers can file a Support Exception for consideration, and the reason for the requirement (expectation: rare) must be clarified.
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Epic Goal
The openshift-sdn CNI plug-in is sunsetting according to the following progression:
- deprecation notice delivered at 4.14 (Release Notes, What's Next presentation)
- removal as an install-time option at 4.15+
- removal as an option and EOL support at 4.17 GA
Why is this important?
All development effort is directed to the default primary CNI plug-in, ovn-kubernetes, which has feature parity with the older openshift-sdn CNI plug-in that has been feature frozen for the entire 4.x timeframe. In order to best serve our customers now and in the future, we are reducing our support footprint to the dominant plug-in, only.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- The openshift-sdn CNI plug-in will no longer be an install-time option for newly installed 4.15+ clusters across installation options.
- Customer clusters currently using openshift-sdn that upgrade to 4.15 or 4.16 with openshift-sdn will remain fully supported.
- EUS customers using openshift-sdn on an earlier release (e.g. 4.12 or 4.14) will still be able to upgrade to 4.16 and receive full support of the openshift-sdn plug-in.
Open questions::
- Will clusters using openshift-sdn and upgrading from earlier versions to 4.15 and 4.16 still be supported?
- YES
- My customer has a hard requirement for the ability to install openshift-sdn 4.15 clusters. Is there any exceptions to support that?
- Customers can file a Support Exception for consideration, and the reason for the requirement (expectation: rare) must be clarified.
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
User Story:
As a (user persona), I want to be able to:
- Have OpenShiftSDN (openshift-sdn CNI plug-in) no longer be an option for networkType, making the only supported value for the network OVNKubernetes
so that I can achieve
- The removal of the openshift-sdn CNI plug-in at install-time for 4.15+
Acceptance Criteria:
Description of criteria:
- Upstream documentation
- Point 1
- Point 2
- Point 3
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- (optional)[ https://github.com/openshift/enhancements/blob/master/enhancements/network/sdn-live-migration.md#rollback|https://github.com/openshift/enhancements/blob/master/enhancements/network/sdn-live-migration.md#rollback]
- https://github.com/openshift/installer/blob/f60ebb065b4242586f7afacc5f2be8afddbdfbde/pkg/types/validation/installconfig.go#L333C1-L333C85
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
Address technical debt around self-managed HCP deployments, including but not limited to
- CA ConfigMaps into the trusted bundle for both the CPO and Ignition Server, improving trust and security.
- Create dual stack clusters through CLI with or without default values, ensuring flexibility and user preference in network management.
- Utilize CLI commands to disable default sources, enhancing customizability.
- Benefit from less intrusive remote write failure modes,.
- ...
Users are encountering an issue when attempting to "Create hostedcluster on BM+disconnected+ipv6 through MCE." This issue is related to the default settings of `--enable-uwm-telemetry-remote-write` being true. Which might mean that that in the default case with disconnected and whatever is configured in the configmap for UWM e.g ( minBackoff: 1s url: https://infogw.api.openshift.com/metrics/v1/receive Is not reachable with disconneced. So we should look into reporting the issue and remdiating vs. Fataling on it for disconnected scenarios.
Version-Release number of selected component (if applicable):
How reproducible:
Steps to Reproduce:
1. 2. 3.
Actual results:
Expected results:
Additional info:
In MCE 2.4, we currently document to disable `--enable-uwm-telemetry-remote-write` if the hosted control plane feature is used in a disconnected environment. https://github.com/stolostron/rhacm-docs/blob/lahinson-acm-7739-disconnected-bare-[…]s/hosted_control_planes/monitor_user_workload_disconnected.adoc Once this Jira is fixed, the documentation needs to be removed, users do not need to disable `--enable-uwm-telemetry-remote-write`. The HO is expected to fail gracefully on `--enable-uwm-telemetry-remote-write` and continue to be operational.
The CLI cannot create dual stack clusters with the default values. We need to create the proper flags to enable the HostedCluster to be a dual stack one using the default values
This can be based on the exising CAPI agent provider workflow which already has an env var flag for disconnected
Epic Goal*
There was an epic / enhancement to create a cluster-wide TLS config that applies to all OpenShift components:
https://issues.redhat.com/browse/OCPPLAN-4379
https://github.com/openshift/enhancements/blob/master/enhancements/kube-apiserver/tls-config.md
For example, this is how KCM sets --tls-cipher-suites and --tls-min-version based on the observed config:
https://issues.redhat.com/browse/WRKLDS-252
https://github.com/openshift/cluster-kube-controller-manager-operator/pull/506/files
The cluster admin can change the config based on their risk profile, but if they don't change anything, there is a reasonable default.
We should update all CSI driver operators to use this config. Right now we have a hard-coded cipher list in library-go. See OCPBUGS-2083 and OCPBUGS-4347 for background context.
Why is this important? (mandatory)
This will keep the cipher list consistent across many OpenShift components. If the default list is changed, we get that change "for free".
It will reduce support calls from customers and backport requests when the recommended defaults change.
It will provide flexibility to the customer, since they can set their own TLS profile settings without requiring code change for each component.
Scenarios (mandatory)
As a cluster admin, I want to use TLSSecurityProfile to control the cipher list and minimum TLS version for all CSI driver operator sidecars, so that I can adjust the settings based on my own risk assessment.
Dependencies (internal and external) (mandatory)
None, the changes we depend on were already implemented.
Contributing Teams(and contacts) (mandatory)
Our expectation is that teams would modify the list below to fit the epic. Some epics may not need all the default groups but what is included here should accurately reflect who will be involved in delivering the epic.
- Development -
- Documentation -
- QE -
- PX -
- Others -
Acceptance Criteria (optional)
Provide some (testable) examples of how we will know if we have achieved the epic goal.
Drawbacks or Risk (optional)
Reasons we should consider NOT doing this such as: limited audience for the feature, feature will be superseded by other work that is planned, resulting feature will introduce substantial administrative complexity or user confusion, etc.
Done - Checklist (mandatory)
The following points apply to all epics and are what the OpenShift team believes are the minimum set of criteria that epics should meet for us to consider them potentially shippable. We request that epic owners modify this list to reflect the work to be completed in order to produce something that is potentially shippable.
- CI Testing - Basic e2e automationTests are merged and completing successfully
- Documentation - Content development is complete.
- QE - Test scenarios are written and executed successfully.
- Technical Enablement - Slides are complete (if requested by PLM)
- Engineering Stories Merged
- All associated work items with the Epic are closed
- Epic status should be "Release Pending"
Goal:
As an administrator, I would like to use my own managed DNS solution instead of only specific openshift-install supported DNS services (such as AWS Route53, Google Cloud DNS, etc...) for my OpenShift deployment.
Problem:
While cloud-based DNS services provide convenient hostname management, there's a number of regulatory (ITAR) and operational constraints customers face prohibiting the use of those DNS hosting services on public cloud providers.
Why is this important:
- Provides customers with the flexibility to leverage their own custom managed ingress DNS solutions already in use within their organizations.
- Required for regions like AWS GovCloud in which many customers may not be able to use the Route53 service (only for commercial customers) for both internal or ingress DNS.
- OpenShift managed internal DNS solution ensures cluster operation and nothing breaks during updates.
Dependencies (internal and external):
- DNS work for KNI
- https://docs.google.com/document/d/1VsukDGafynKJoQV8Au-dvtmCfTjPd3X9Dn7zltPs8Cc/edit
- This is a prerequisite for the internal clusters epic: https://docs.google.com/document/d/1gxtIW6OlasVQtQLTyOl6f9H9CMuxiDNM5hQFNd3xubE/edit#
Prioritized epics + deliverables (in scope / not in scope):
- Ability to bootstrap cluster without an OpenShift managed internal DNS service running yet
- Scalable, cluster (internal) DNS solution that's not dependent on the operation of the control plane (in case it goes down)
- Ability to automatically propagate DNS record updates to all nodes running the DNS service within the cluster
- Option for connecting cluster to customers ingress DNS solution already in place within their organization
Estimate (XS, S, M, L, XL, XXL):
Previous Work:
Open questions:
Link to Epic: https://docs.google.com/document/d/1OBrfC4x81PHhpPrC5SEjixzg4eBnnxCZDr-5h3yF2QI/edit?usp=sharing
User Story:
As a (user persona), I want to be able to:
- Capability 1
- Capability 2
- Capability 3
so that I can achieve
- Outcome 1
- Outcome 2
- Outcome 3
Acceptance Criteria:
Description of criteria:
- Upstream documentation
- Point 1
- Point 2
- Point 3
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- (optional) https://github/com/link.to.enhancement/
- (optional) https://issues.redhat.com/link.to.spike
- Engineering detail 1
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
Append Infra CR with only the GCP PlatformStatus field (without any other fields esp the Spec) set with the LB IPs at the end of the bootstrap ignition. The theory is that when Infra CR is applied from the bootstrap ignition, first the infra manifest is applied. As we progress through all the other assets in the ignition files, Infra CR appears again but with only the LB IPs set. That way it will update the existing Infra CR already applied to the cluster.
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- At this point in the feature, we would have a working in-cluster CoreDNS pod capable of resolving API and API-Int URLs.
This Epic details that work required to augment this CoreDNS pod to also resolve the *.apps URL. In addition, it will include changes to prevent Ingress Operator from configuring the cloud DNS after the ingress LBs have been created.
Why is this important?
- …
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
User Story:
As a (user persona), I want to be able to:
- Capability 1
- Capability 2
- Capability 3
so that I can achieve
- Outcome 1
- Outcome 2
- Outcome 3
Acceptance Criteria:
Description of criteria:
- Upstream documentation
- Point 1
- Point 2
- Point 3
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- https://github.com/openshift/api/pull/1685 introduced updates that allows the LB IPs to be added to GCPPlatformStatus along with the state of DNS for the cluster.
- Update cluster-ingress-operator to add the Ingress LB IPs when DNSType is `ClusterHosted`
- In this state, Within https://github.com/openshift/api/blob/master/operatoringress/v1/types.go set the DNSManagementPolicy to Unmanaged within the DNSRecordSpec when the DNS manifest has customer Managed DNS enabled.
- With the DNSManagementPolicy set to Unmanaged, the IngressController should not try to configure DNS records.
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.